Is Duplicate Data Slowing Your Company’s Growth And Profit?
Data is the backbone of most businesses – without it, where would our organizations be? And yet, there is a fundamental flaw in data management for many organizations. The issue is duplication. In other words, much of the data appears more than once throughout our processes. Data duplication can be a key indicator of flawed workflow and inefficient operations.
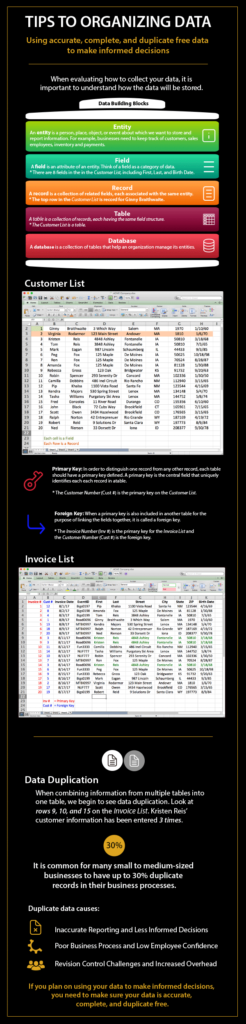
Duplication might not sound like a huge issue, but at a time when most businesses are striving to improve efficiency and performance, duplicate records have the potential to create real business problems. We find data duplication is most apparent when organizations try to report on the information they are capturing. When trying to analyze our data, duplication makes things far more difficult. It is common for many small to medium-sized businesses to have up to 30% duplicate records in their business processes.
So what impact can duplicate records have?
Inaccurate reporting and less informed decisions
If you are planning on using your data to make informed decisions and forecast what you should be doing more of for future business growth, you need to make sure that your data is accurate, complete and duplicate free. Decisions based on poor quality data are no more reliable and accurate as those made on assumptions. Cluttering up your database with poor quality data will impact your ability to make informed judgments and decisions about the state and future of your business.
Poor business processes and low employee confidence
Disadvantages of data redundancy include an unnecessary increase in the amount of time entering data, and the likelihood of data corruption being a direct result of redundancy. Other disadvantages include the likelihood of inconsistency of data as well as the decreased efficiency of a database.
An unforeseen result of poor processes is how it impacts employees. When employees start to lose confidence in the processes because of the number of duplicates and inaccurate data, they can revert to using isolated methods of record management, such as Excel and Post-It notes. Using such business processes limit your access to important information and inadvertently limit the growth of your business. As your business grows, so does the amount of data, making the isolated methods unmanageable and increasing the potential to lose valuable information.
Revision control challenges and increased overhead
A difficult problem becomes obvious when data needs to be revised or a field value changes, multiple locations need to be updated. For example, if an employee moves, we need to change the values of their Street, City, State and Zip in multiple records. This problem is compounded if we forget to change the values in any of the records. The database would then have inconsistent data in different locations.
Managing multiple locations for data requires increased labor and overhead. Many businesses will often justify the extra cost believing it is required to manage the flow of information. In reality, this cost is a reflection of an inefficient workflow and can be eliminated by revising data management processes.
Nearly one hundred percent of the small businesses we start working with use multiple software packages to operate their businesses on a daily basis. Generally speaking, these businesses use one software system for accounting, Microsoft Excel for maintaining inventory and production data, and additional software systems for human resources and customer relationship management. None of these systems, unfortunately, are electronically tied to one another; they require the input of the same data multiple times in each system separately. As a small business grows, it is forced to develop internal processes to “work around” or accommodate this lack of integration across various information systems. Working within these inefficient processes, the business comes to accept such inefficiencies as “status quo.”
And what’s the remedy?
To counteract the problem of data duplication, you need to look at your own unique data requirements and data issues to create a deduplication strategy. Your strategy will involve a blend of human insight, process management, and data processing to help identify how the data is collected and utilized. You should take into account how strict you want to be with data duplication, in terms of developing a balance between having clean data and not losing valuable information. The process of cleaning up your existing data will involve analyzing your current database to identify potential duplicate records, and unraveling these to identify definite duplicates or where, for instance, it’s different information for the same employee or customer.
Here is a six-step strategy to reduce data redundancy.
Click to view the PDF
1. Identify primary sources of duplicate data
One of the first steps to fixing your data duplication is identifying the source of where data enters the system. Look at data entry errors and patterns to determine the primary internal and external sources of data inaccuracy. Finding these patterns can help point to the sources of error, which you can then go about fixing with changes to either processes or management techniques.
2. Reduce redundant data
Entering information is a time-consuming process for your employees. Reducing the number of times employees need to input the same information can provide immense benefit. Eliminate any unnecessary data, so only useful data is processed. If the data does not provide insight, visibility, or value to reporting, it may not need to be added to the database. One of the best ways to do this is by regularly reviewing your forms and documents to check that all the requested information is relevant and necessary for your business processes.
How can forms help us reduce data-entry errors, you may wonder. Modern data management tools and forms provide the ability to pull information from other sources, removing the need to enter it twice. By optimizing and automating your forms, you minimize the possibility of double-entry and cut down the amount of data your employees need to process. This reduces the chances for your employees to input errors in the system.
3. Standardize processes
Standardizing both your data collection and data entry processes helps improve your overall accuracy and consistency. By developing and maintaining standard processes, your employees know what to expect, and they understand how the data is utilized. This helps employees develop a pattern of operation, allowing them to work both quickly and accurately. In addition to being helpful for your employees, standardization is necessary if you’re looking to automate any of your data entry processes.
4. Train employees on the importance of the data being collected
Before establishing a process for data entry, it is important to help employees see the value and importance of the data being collected. Before employees start entering data, demonstrate how inaccuracy can negatively affect their workflow and the business. This basic understanding of the relevance and importance of their position helps employees feel more responsible for the data, improving their overall effectiveness and accuracy.
5. Prioritize accuracy over speed
While speed is important for any workflow or process, accuracy is more important when it comes to data entry. Rushing a task as detail-oriented as data entry is bound to end with more errors. Instead, focus on accuracy as their primary objective by emphasizing accuracy during training and setting accuracy performance goals.
6. Enable automated tools and processes
Entering data manually is expensive. Additionally, the monotony of data entry makes it a highly error-prone job with a high turnover rate. To help combat the costs associated with manual data entry tasks, identify tools and processes that will help you automate and streamline as much data entry as possible.
As you establish your processes, look for areas to incorporate tools like www.xtiri.com into your workflow. It may not be possible to completely eliminate data entry, but with the appropriate automated system and processes, you can remove the human factor, reducing errors, labor costs and long-term risks to your organization.
Obviously, it costs money to eliminate duplicate data, but it is worth the investment as the costs are likely to be significantly lower than the money you will lose otherwise. While the mentioned steps may not entirely eliminate duplicate data, they will help your employees reduce the chances to make mistakes and allow more time to review and analyze your data.
For small businesses that have discovered they suffer from duplicate entry issues and are considering whether or not to replace existing systems (and internal processes) with a more automated software system, they should ask themselves one simple question – “How much money does entering data in each of our existing systems cost us each year?” In most cases, you will find that eliminating duplicate data will save you time, money, and help your organization become more efficient. The increased quality of your data will contribute to your strategic planning and growth.
If you would like help organizing your data and minimizing duplicate processes, please contact XTIRI at 1-877-505-9140.
XTIRI is a digital platform that helps companies bridge the gap between their business process and their valuable data. XTIRI provides access to all types of raw data and lets you cleanse, transform and shape it for any analytic purpose. As a result, you can gain deeper insights, share new discoveries, and automate decision-making processes across your business. For more information, visit www.xtiri.com